怎么用chatgpt分析文檔 使用LLM模型,用LangChain建立一個(gè)基于文檔的問題回答系統(tǒng)。
這里使用LLM模型作為,向量存儲(chǔ)作為與框架。
1. 緒論
這篇博文深入探討了創(chuàng)建一個(gè)高效的基于文檔的問題解答系統(tǒng)所涉及的步驟。通過利用和這兩項(xiàng)尖端技術(shù)的力量怎么用chatgpt分析文檔,我們利用了大型語言模型(LLM)的最新進(jìn)展,包括 GPT-3和。
是一個(gè)專門為開發(fā)語言模型驅(qū)動(dòng)的應(yīng)用程序而設(shè)計(jì)的強(qiáng)大框架,是我們項(xiàng)目的基礎(chǔ)。它為我們提供了必要的工具和能力,以創(chuàng)建一個(gè)能夠根據(jù)具體文件準(zhǔn)確回答問題的智能系統(tǒng)。
為了提高我們問題回答系統(tǒng)的性能和效率,我們整合了,這是一個(gè)高效的矢量數(shù)據(jù)庫,以建立高性能的矢量搜索應(yīng)用而聞名。通過利用它的能力,我們可以顯著提高我們系統(tǒng)的搜索和檢索過程的速度和準(zhǔn)確性。
我們?cè)谶@個(gè)項(xiàng)目中的主要重點(diǎn)是通過完全依靠目標(biāo)文件中包含的信息來生成精確的和上下文感知的答案。通過將語義搜索的優(yōu)勢(shì)與GPT等LLM的卓越能力相結(jié)合怎么用chatgpt分析文檔,我們實(shí)現(xiàn)了一個(gè)最先進(jìn)的文檔QnA系統(tǒng)。
通過這篇博文,我們旨在引導(dǎo)讀者完成建立他們自己的前沿的基于文檔的問題回答系統(tǒng)的過程。通過利用人工智能技術(shù)的最新進(jìn)展,我們展示了結(jié)合語義搜索和大型語言模型的力量,最終形成一個(gè)高度準(zhǔn)確和高效的系統(tǒng),用于回答基于特定文檔的問題。
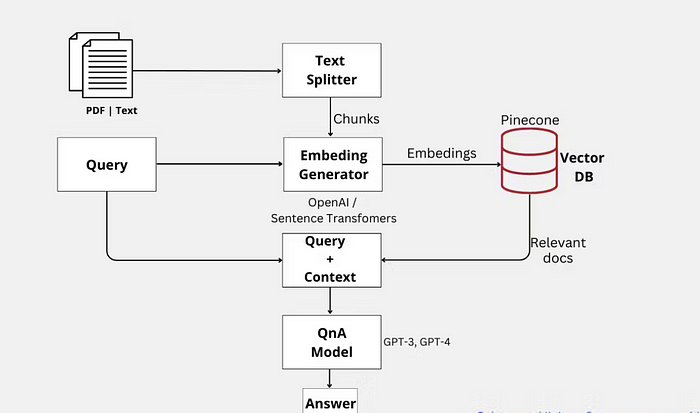
2. 針對(duì)具體環(huán)境的答案:
語義搜索+GPT QnA可以通過將答案建立在相關(guān)文件的具體段落上,從而產(chǎn)生更多針對(duì)具體語境和精確的答案。然而,經(jīng)過微調(diào)的GPT模型可能會(huì)根據(jù)模型中嵌入的一般知識(shí)生成答案,而這些答案可能不太精確,或者與問題的上下文無關(guān)。
3. 模塊
提供對(duì)幾個(gè)主要模塊的支持:
模型: 支持的各種模型類型和模型集成。索引: 當(dāng)與你自己的文本數(shù)據(jù)相結(jié)合時(shí),語言模型往往更加強(qiáng)大 - 本模塊涵蓋了這樣做的最佳實(shí)踐。連鎖: 鏈超越了單一的LLM調(diào)用,是一系列的調(diào)用(無論是對(duì)LLM還是不同的工具)。為鏈提供了一個(gè)標(biāo)準(zhǔn)接口,與其他工具進(jìn)行了大量的整合,并為常見的應(yīng)用提供了端到端的鏈。索引: 當(dāng)與你自己的文本數(shù)據(jù)相結(jié)合時(shí),語言模型往往更加強(qiáng)大 - 本模塊涵蓋了這樣做的最佳實(shí)踐。4. 讓我們深入了解實(shí)際的實(shí)施情況:
導(dǎo)入圖書館:
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
首先,我們需要使用中的從一個(gè)目錄中加載文檔。在這個(gè)例子中,我們假設(shè)文件存儲(chǔ)在一個(gè)名為 "data "的目錄中。
directory = '/content/data' #keep multiple files (.txt, .pdf) in data folder.
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)
現(xiàn)在,我們需要將文件分割成更小的塊狀物進(jìn)行處理。我們將使用中的,它默認(rèn)情況下會(huì)嘗試在字符["\n\n", "\n", " ", ""]上分割。
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
docs = split_docs(documents)
print(len(docs))
一旦文件被分割怎么用chatgpt分析文檔,我們需要使用的語言模型來嵌入它們。首先,我們需要安裝庫。
!pip install tiktoken -q
現(xiàn)在,我們可以使用的類來嵌入文檔。
embeddings = OpenAIEmbeddings(model_name="ada")
query_result = embeddings.embed_query("Hello world")
len(query_result)
是一個(gè)高性能的向量數(shù)據(jù)庫。它能對(duì)高維向量進(jìn)行快速、準(zhǔn)確的相似性搜索。憑借其用戶友好的API、可擴(kuò)展性和先進(jìn)的算法,開發(fā)者可以輕松處理大型矢量數(shù)據(jù),實(shí)現(xiàn)實(shí)時(shí)檢索,并建立高效的推薦系統(tǒng)和搜索引擎。
!pip install pinecone-client -q
然后,我們可以初始化并創(chuàng)建一個(gè)索引。
pinecone.init(
api_key="pinecone api key",
environment="env"
)
index_name = "langchain-demo"
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
我們正在使用.()方法創(chuàng)建一個(gè)新的向量索引。這個(gè)方法需要三個(gè)參數(shù):
docs: 一個(gè)使用 分割成小塊的文件列表。這些小塊將被編入的索引,以方便以后搜索和檢索相關(guān)文件。: 類的一個(gè)實(shí)例,它負(fù)責(zé)使用的語言模型將文本數(shù)據(jù)轉(zhuǎn)換為嵌入(即數(shù)字表示法)。這些嵌入將被存儲(chǔ)在索引中并用于相似性搜索。: 一個(gè)代表索引名稱的字符串。這個(gè)名字用于識(shí)別數(shù)據(jù)庫中的索引,它應(yīng)該是唯一的,以避免與其他索引沖突。: 類的一個(gè)實(shí)例,它負(fù)責(zé)使用的語言模型將文本數(shù)據(jù)轉(zhuǎn)換為嵌入(即數(shù)字表示法)。這些嵌入將被存儲(chǔ)在索引中并用于相似性搜索。
.()方法處理輸入的文檔,使用提供的實(shí)例生成嵌入,并以指定的名稱創(chuàng)建一個(gè)新的索引。產(chǎn)生的索引對(duì)象可以進(jìn)行相似性搜索,并根據(jù)用戶的查詢檢索相關(guān)的文檔。
5. 尋找類似的文件:
現(xiàn)在,我們可以定義一個(gè)函數(shù)來尋找基于給定查詢的類似文件。
def get_similiar_docs(query, k=2, score=False): # we can control k value to get no. of context with respect to question.
if score:
similar_docs = index.similarity_search_with_score(query, k=k)
else:
similar_docs = index.similarity_search(query, k=k)
return similar_docs
6. 使用和 LLM進(jìn)行問題回答:
有了必要的組件,我們現(xiàn)在可以使用的類和一個(gè)預(yù)建的問題回答鏈來創(chuàng)建一個(gè)問題回答系統(tǒng)。
from langchain.llm import AzureOpenAI
model_name = "text-davinci-003"
llm = AzureOpenAI(model_name=model_name)
chain = load_qa_chain(llm, chain_type="stuff") #we can use map_reduce chain_type also.
def get_answer(query):
similar_docs = get_similiar_docs(query)
print(similar_docs)
answer = chain.run(input_documents=similar_docs, question=query)
return answer
7. 查詢和回答的例子:
最后,讓我們用一些實(shí)例查詢來測(cè)試我們的問題回答系統(tǒng)。
query = "How is India's economy?"
answer = get_answer(query)
print(answer)
query = "How have relations between India and the US improved?"
answer = get_answer(query)
print(answer)
在這里,我們將獲得帶有特定查詢的上下文,然后我們將查詢和上下文作為提示傳遞給LLM模型以獲得響應(yīng)。
8. 結(jié)論:
在這篇博文中,我們展示了利用和構(gòu)建一個(gè)基于文檔的問題回答系統(tǒng)的過程。通過利用語義搜索和大型語言模型的能力,這種方法為從大量的文件集中提取有價(jià)值的信息提供了一個(gè)強(qiáng)大而通用的解決方案。此外,這個(gè)系統(tǒng)可以很容易地進(jìn)行定制,以滿足個(gè)人需求和特定領(lǐng)域,為用戶提供一個(gè)高度適應(yīng)性和個(gè)性化的解決方案。
免責(zé)聲明:本文系轉(zhuǎn)載,版權(quán)歸原作者所有;旨在傳遞信息,不代表本站的觀點(diǎn)和立場(chǎng)和對(duì)其真實(shí)性負(fù)責(zé)。如需轉(zhuǎn)載,請(qǐng)聯(lián)系原作者。如果來源標(biāo)注有誤或侵犯了您的合法權(quán)益或者其他問題不想在本站發(fā)布,來信即刪。
聲明:本站所有文章資源內(nèi)容,如無特殊說明或標(biāo)注,均為采集網(wǎng)絡(luò)資源。如若本站內(nèi)容侵犯了原著者的合法權(quán)益,可聯(lián)系本站刪除。